

※当サイトにはプロモーションが含まれています。
サーチコンソールでサイトマップが「取得できませんでした」とエラーになる。
何とかしてくれ!
頑張ってみるにゃ・・・。
Googleのサーチコンソール(Google Search Console)を使って、サイトマップを送信している方も多いと思います。
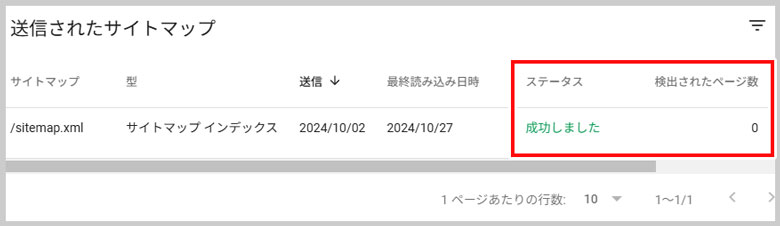
今回、https://(ドメイン名)/sitemap.xml
の送信ステータスは「成功しました」になるのですが、検出されたページ数は0件。
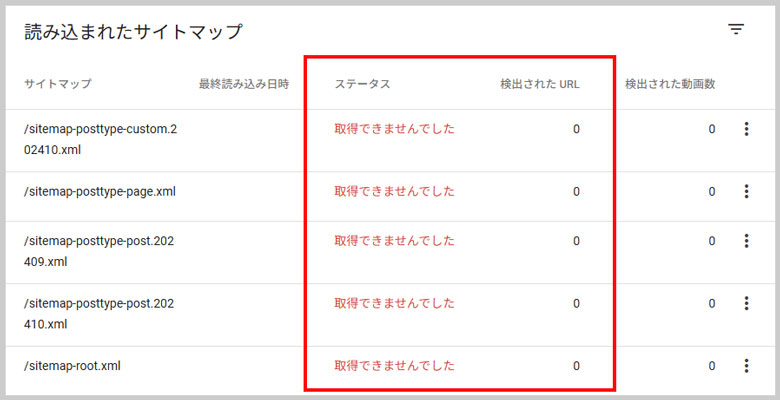
さらに詳細を見てみると、各種サイトマップが「取得できませんでした」とエラーになっていました。
なお、クライアントはワードプレス(WordPress)でサイトを作成しています。
そして、使用しているワードプレスのプラグインは「XML Sitemap & Google News」でした。
また「XML Sitemap & Google News」の公式サイト、グーグルのサポートにも同様の報告をいくつか見つけました。
しかし、解決方法が記載されているものは発見できず・・・。
仕方なく自分で調べたので、その内容を備忘録として残しておきたいと思います。
※こだわりがなければ、「XML Sitemap Generator for Google」のプラグインを使う事をオススメします
プラグイン「XML Sitemap & Google News」の修正方法
最初に結論を書きます。
今回、Google Search Consoleのサイトマップが「取得できませんでした」となってしまう原因は、プラグインの「XML Sitemap & Google News」にありました。
その為、プラグインのコード自体を書き換えましたが、修正される際は自己責任でお願い致します。
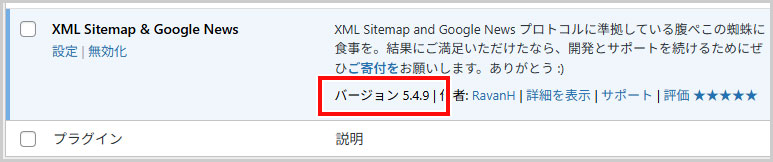
今回、修正したバージョンは、5.4.9です。
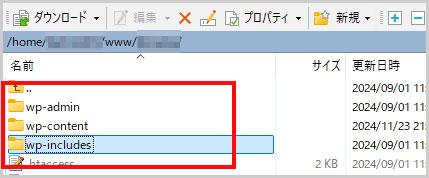
①FTPソフトでワードプレスのルートディレクトリに移動
FTPソフトでワードプレスのルートディレクトリに移動します。
通常は、public_htmlやwww、homeなどのディレクトリがこれに該当し、wp-admin、wp-content、wp-includesのフォルダがあります。
②XML Sitemap & Google Newsのフォルダに移動する
wp-contentフォルダ > pluginsフォルダを開きます。
すると、「xml-sitemap-feed」というフォルダがあるので、これが「XML Sitemap & Google News」のプラグインになります。
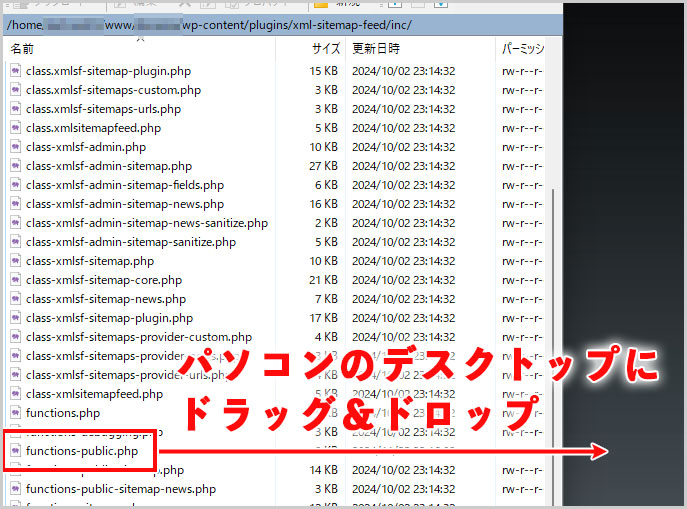
③functions-public.phpファイルをダウンロード
xml-sitemap-feedフォルダ > incフォルダ を開きます。
functions-public.phpファイルがあると思うので、デスクトップにドラッグ&ドロップなどしてダウンロードします。
④functions-public.phpを編集する
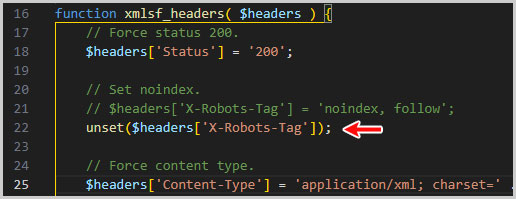
functions-public.phpの21行目付近に下記の記述があると思います。
// Set noindex.
$headers['X-Robots-Tag'] = 'noindex, follow';
この内容を以下の様に修正します。
// Set noindex.
//$headers['X-Robots-Tag'] = 'noindex, follow';
unset($headers['X-Robots-Tag']);
21行目に記載されていた内容は、半角のスラッシュ(/)を2つ記載してコメントアウトしています。
実際に記述すると次の画像のようになります。
あとは、修正したfunctions-public.phpをアップロードして上書きして保存すればOKです。
補足:XML Sitemap & Google Newsで「取得できませんでした」になる所見
XML Sitemap & Google Newsに関する「取得できませんでした」の不具合については、2024年頃から散見されています。
その為、旧バージョン、5.3.6にすることで解決できるという情報も見かけましたが、おそらく解決しないのではないかと思われます(未検証です)。
その理由として、旧バージョンである5.3.6のコードも確認しましたが、原因と思われる下記の記述があるからです。
$headers['X-Robots-Tag'] = 'noindex, follow';その為、このトラブルの原因は、Google Search Consoleの仕様が変わったのかな?と推測しています。
サイトマップが取得できない原因を確認した手順
サイトマップが取得できない原因を確認した手順について記載しておきます。
①Google Search ConsoleのURL検査で確認
Google Search Consoleにログインします。
上部にあるURL検査ボックスに「取得できませんでした」と表示されるサイトマップのURLを入力して検査します。

②URL公開テストの結果を確認
続いて、「公開URLをテスト」を選択します。
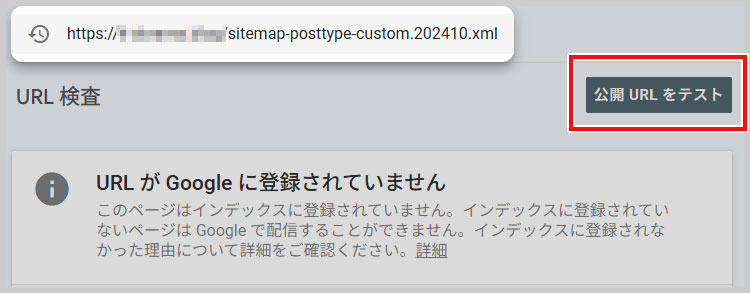
すると検査結果が表示されると思いますので、その内容を確認します。
今回は、「いいえ、X-Robots-Tag Httpヘッダーでnoindexが検出されました」と表示されました。
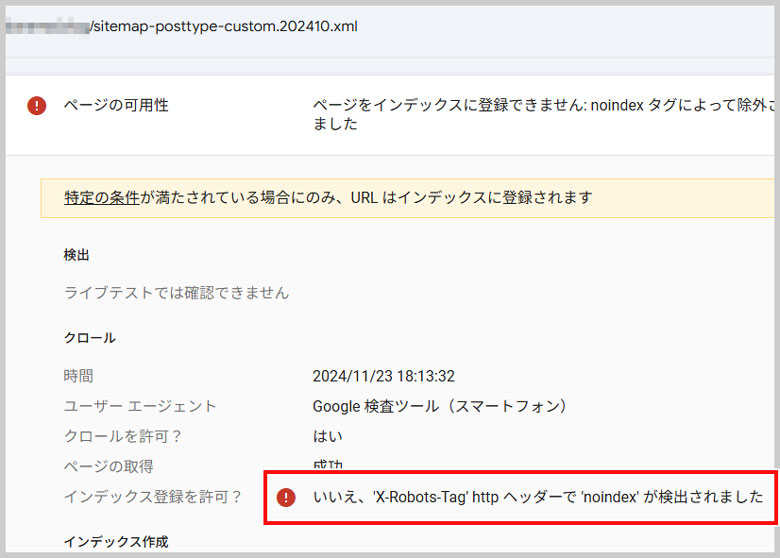
どうやら、このX-Robots-Tagで、noindexを設定していることが、サイトマップで「取得できませんでした」というエラーになっている原因のようです。
HTTPヘッダーで使用されるタグで、検索エンジンにページやファイルのインデックス登録の可否やクローリングの指示を伝えるために使われます。
HTML内の<meta name=”robots”>タグと同様の役割を持ちますが、HTMLにアクセスしなくてもヘッダーで設定できる点が特徴です。
特にPDFや画像などHTML以外のリソースの制御に便利で、SEO管理やセキュリティのために活用されます。
③プラグイン「XML Sitemap & Google News」の修正
プラグインの「XML Sitemap & Google News」の管理画面には、X-Robots-Tagの設定をする箇所はありませんでした。
その為、前項で紹介した方法で、X-Robots-Tagの設定を無効にしました。
そして、同じように検査をしたところ、「いいえ、X-Robots-Tag Httpヘッダーでnoindexが検出されました」のエラー表示が消えました。
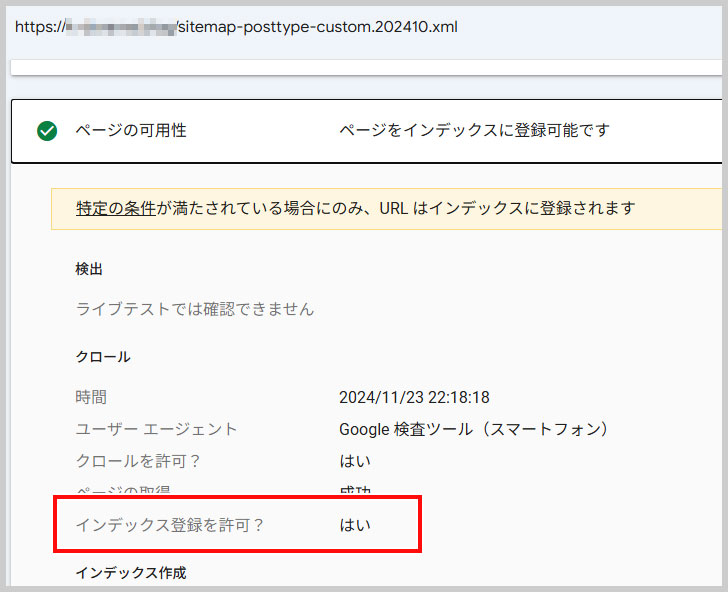
これで、Googleがサイトマップを確認できるようになったと思うので、しばらく様子を見ます。
なお、Googleの公式ページでは、URLの数が500以下のサイトにおいて、サイトマップを登録する必要はないとアナウンスしています。
追記:2024.11.26
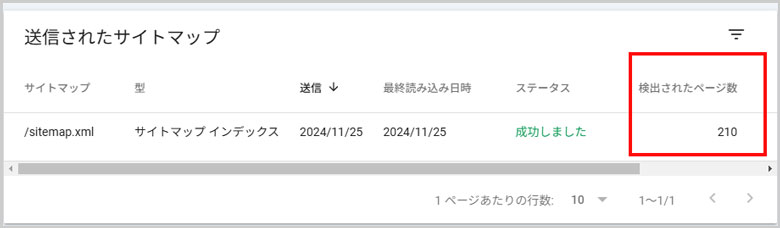
サイトマップを再送信後、24時間経過したらサイトマップが更新されていました。
無事、検出されたページ数が、0から210件になりました。
追記:2024.12.24
その後、「XML Sitemap & Google News」のプラグインは、やはりエラーになることが多かったです。
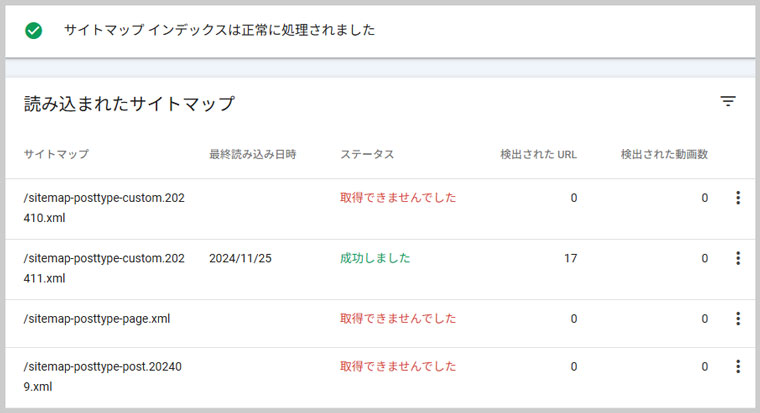
その為、「XML Sitemap Generator for Google」のプラグインと入れ替えて様子を見たところ、明らかに「XML Sitemap Generator for Google」の方が動作が安定するので、プラグインを入れ替えました。
入替え方法は難しくなく、「XML Sitemap & Google News」をアンインストールしてから、「XML Sitemap Generator for Google」をインストールして有効化すればOKです。





