

※当サイトにはプロモーションが含まれています。
最近、ブログへのアクセスが減ってきたにゃ。
このサイトでは、アクセスされる記事の傾向として、PHPやCSS、JavaScriptといった技術系の記事が全体の約50%を占め、残りの50%が雑記系の記事でした。
しかし日を追うごとに、技術系記事へのアクセスが減り、現在では技術系が約20%、雑記系が80%ぐらいになってきました。
つまり、技術系の記事へのアクセス数が減ってきました。
その原因のひとつとして、AIクローラーによる情報収集の影響があるのかな・・・と感じています。
そこで今回は、AIクローラーをブロックする方法についてまとめてみました。
主要なAIクローラー・AIサービスについて
主要なAIクローラー・AIサービスについてまとめました。
| User-agent名 | 運営会社/サービス | 主な用途 |
|---|---|---|
| GPTBot | OpenAI(ChatGPT) | ChatGPTの学習用クローラー |
| CCBot | Common Crawl | Webアーカイブ収集(多数のAI学習に利用) |
| ClaudeBot | Anthropic(Claude) | Claudeの学習データ収集 |
| Google-Extended | Google(Gemini等) | Gemini等のAIによるWebデータ収集 |
| PerplexityBot | Perplexity.ai | AI検索サービスのクローラー |
| Microsoft-Assistant | Microsoft Copilot / Bing | Copilot や AI検索(Bing)向けのデータ収集 |
| Bytespider | ByteDance(TikTok) | TikTokやAI開発向けのデータ取得 |
| facebookexternalhit | Meta(Facebook, LLaMA) | シェア用キャッシュ収集(AI学習に使われる可能性あり) |
| Applebot | Apple(Siri, Spotlight) | Siri、Spotlight検索、AI機能の一部に活用 |
| Amazonbot | Amazon | Alexa・商品分析・AI学習など |
| YandexBot | Yandex(ロシア) | 検索・AI・画像認識サービス用 |
| YouBot | You.com(AI検索) | AIチャット検索向けのクローラー |
ログを見た限り、このサイトで影響が大きそうなのは、GPTBotとPerplexityBotの2つでした。
AIクローラーをブロックするrobots.txtの記述方法
robots.txtっていうのはどういったファイルにゃ?
robots.txtは、検索エンジンやAIクローラーなどのロボットに対して、「このページは見ないで」「ここはOK」といった指示を出すためのファイルです。
通常は、サイトの一番上の階層(ルート)に設置し、特定のページへのクロール制御や、AIによる学習の制限などに使われます。
AIクローラーをブロックするrobots.txtの記述方法です。
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Microsoft-Assistant
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: facebookexternalhit
Disallow: /
User-agent: Applebot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: YandexBot
Disallow: /
User-agent: YouBot
Disallow: /もし、ブロックしたくないAIクローラーがあれば、その行は削除してください。
これを記述してGoogleの検索結果に影響はないのかにゃ?
基本的に、学習用のクロールのブロックと、検索エンジンのインデックス制御は別です。
そのため、AIクローラーをブロックしても、GoogleやYahoo、Bingなどの検索結果には影響しないと考えられます。
ワードプレスでの robots.txt の設置場所について
robots.txt は、ワードプレスのルートディレクトリ(=wp-admin、wp-content、wp-includes が存在する階層)に設置します。
WinSCPやFileZillaなどのFTPソフトを使い、このルートディレクトリに robots.txt をアップロードしてください。
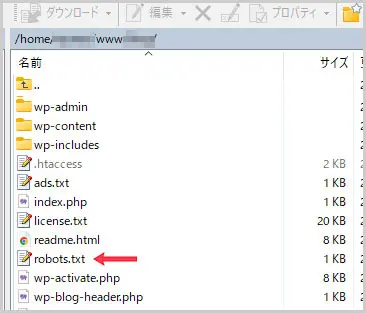
正しく設置されていれば、以下のURLにアクセスすることで内容が表示されます。
https://(ドメイン名)/robots.txt
Cloudflareの「クロールごとに課金」プライベートベータ版について
最近話題になっているのが、Cloudflare(クラウドフレア)が発表した、pay per crawlという仕組み(サービス)です。
これは、AIクローラーがウェブサイトのコンテンツをクロールするたびに、サイト運営者が料金を設定できる仕組みです。
これまでの選択肢は「ブロックする」か「無料で許可する」の二択でしたが、新たに「有料で許可する」という第三の選択肢が加わりました。
2025年7月現在、下記から、プライベートベータ版への申し込みができます。
ベータ版が提供されたら、色々と試してみたいと思います。

追記:Perplexity(パープレキシティ)はステルスクローリングしている
Cloudflare(クラウドフレア)は、米Perplexity AIが運営する「Perplexity」が、一部のWebサイトに対して設けられたクローリング制限を回避している疑いがあると発表しました。
具体的には、Perplexityがユーザーエージェントを偽装し、AIによるスクレイピングを禁止しているサイトであっても、その制限をすり抜けてアクセスしているとしています。
参考:Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives
正直なところ、やっぱりな・・・という印象です。
というのも、Perplexity(パープレキシティ)にはソフトバンクが関与(出資)しており、同社はこれまでもモラルより利益を優先するような姿勢が見受けられるからです。
なお、自分がソフトバンク(SoftBank)を嫌っている理由はいくつかありますが、
許せないのは、数年にわたり、高齢の義母がソフトバンクと不要な契約を複数結ばされたうえ、契約の解除にも誠実に対応してもらえなかったからです。
昨日、自宅近くの特別養護老人ホームの方から「空きがでたので入居されますか?」という連絡をいただきました。 この施設に申し込みをしたのは約6年前、そして義母が亡くなったのが約5年前。 色々とあったな・・・と回顧しつつ、当時 …






